Transformers in NLP are a type of deep learning model that uses self-attention mechanisms to analyze and process natural language data. They are encoder-decoder models that can be used for many applications, including machine translation.
01
Foundation
Datasets & Data
Datasets are collections of data used by AI systems for analysis and training. This data can come in various forms — CSV files, web pages, PDFs, images, videos, or audio recordings. Datasets can grow quite large because, unlike humans, computers need many examples to identify patterns or make comparisons.
For example, if you wanted to use AI to identify the type of animal in a photo or create a resume template, lots of examples would be needed for Generative AI to see a common pattern in order to generate a response. AI takes our data, converts it into a bunch of numbers called vectors, and then looks at those numbers to find a common pattern. Once a pattern is found, an AI model creates a response.
02
Core Concept
Attention Mechanism
In AI we take in lots of data from our datasets to analyze them — but do we need to study every single piece of data equally? When an athlete trains for an event, they may focus on one aspect of their training more than another. Maybe their diet is more focused than their running routine. In AI, instead of processing the entire input equally, the attention mechanism helps the model "pay more attention" to certain parts of the input that are more important for the task at hand.
Take translating from English to Portuguese — an AI model might focus more on specific words in the sentence that are most crucial for understanding the meaning. Instead of processing the entire sentence equally, it dynamically decides which words to focus on based on their relevance. Attention Mechanism processes words through an encoder and decoder process.
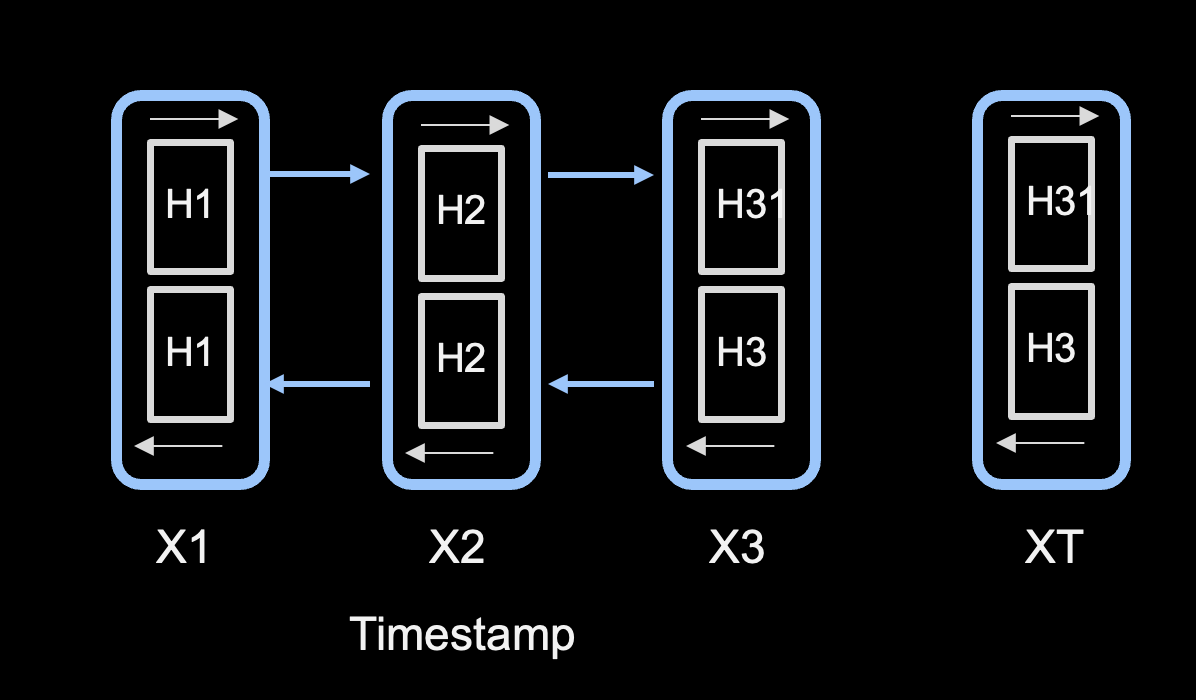
LSTM — Sequential Word Processing (X1, X2, X3)
This illustration shows how a model processes words in a sentence from left to right, based on a timestamp X1, X2, X3. Each word is processed in order and not in parallel. This causes a problem with huge datasets because the training process is not scalable — long lag times can occur based on the length of a sentence.
This architecture is referred to as Long Short-Term Memory (LSTM), a type of recurrent neural network (RNN) used within encoder and decoder components to process sequential data.
To overcome the scalability problem, Transformers use a process called Self Attention. With self attention, all words are sent in parallel to be processed, making it highly scalable for large datasets such as those used with Large Language Models.
03
Model Types
BERT, GPT & Beyond
You may have heard of transformer types such as BERT and GPT. These transformers allow companies to use models on huge amounts of data without having to build their own. These models leverage transfer learning — a model trained on a large general dataset that is then fine-tuned for a specific task. There are also multimodal models such as DALL-E that work with both text and images.
Transfer Learning: Instead of training a model from scratch, you take a model that has already been trained on a massive dataset and fine-tune it for your specific use case. This dramatically reduces compute requirements and training time.
04
Deep Dive
How Transformers Work
Let's look at an example of how Transformers work. The diagram below shows the conversion of a sentence into vectors using encoder/decoder and transformers. With the encoder/decoder process, a sequential model is used — each word is passed through the sentence and converted to a number. Each vector under the embedding layer represents a word; with 9 words, there are 9 vector units.
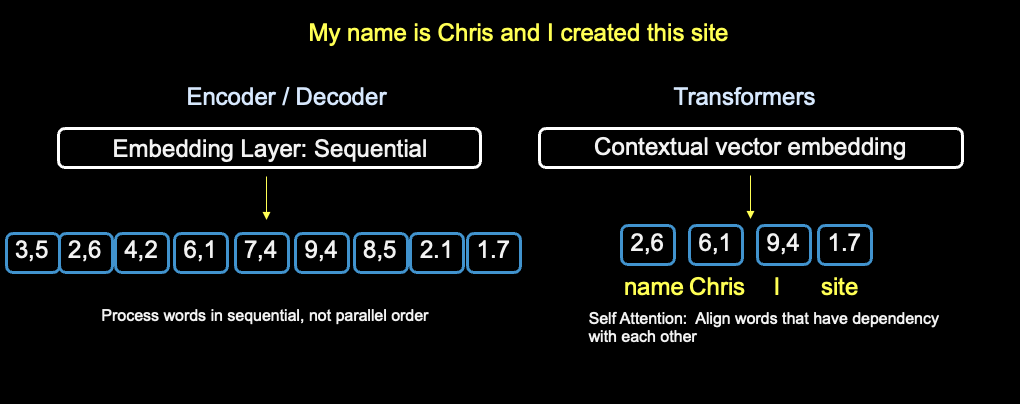
Sequential Encoder/Decoder vs. Transformer Contextual Vector Embedding
Notice the difference between sequential encoder/decoder and Transformers. On the right of the diagram, contextual vector embedding is used. With transformers, words identified with a dependency are selected for conversion. "Chris" has a dependency of "name", and "I" and "site" could have a dependency of "Chris". Contextual embedding maps the context of words as they relate to each other.
This technique is known as soft attention and is one reason why transformers are efficient for use with Large Language Models and use cases involving large amounts of data. By applying self-attention, the transformer model can capture the dependencies between different words in the input sequence and learn to focus on the most relevant words for each position.
Let's take a closer look at the transformer architecture using the example of translating English to Portuguese. The diagram shows multiple instances of encoders and decoders — this enhances the transformer's ability to capture complex patterns in data.
Transformers use encoders and decoders, but not in a sequential pattern. Self attention takes in the fixed vector input of "How are you?" in parallel, and converts it to a different set of vectors using contextual embedding. Once Self Attention has converted the input vectors into contextual vectors, the numbers are passed to the Feed Forward Neural Network, and then to the next encoder.
In the diagram, 3 encoders/decoders are shown — but transformer architectures could have 6 or more. The more processing done with encoders, the more accurate the model's output.
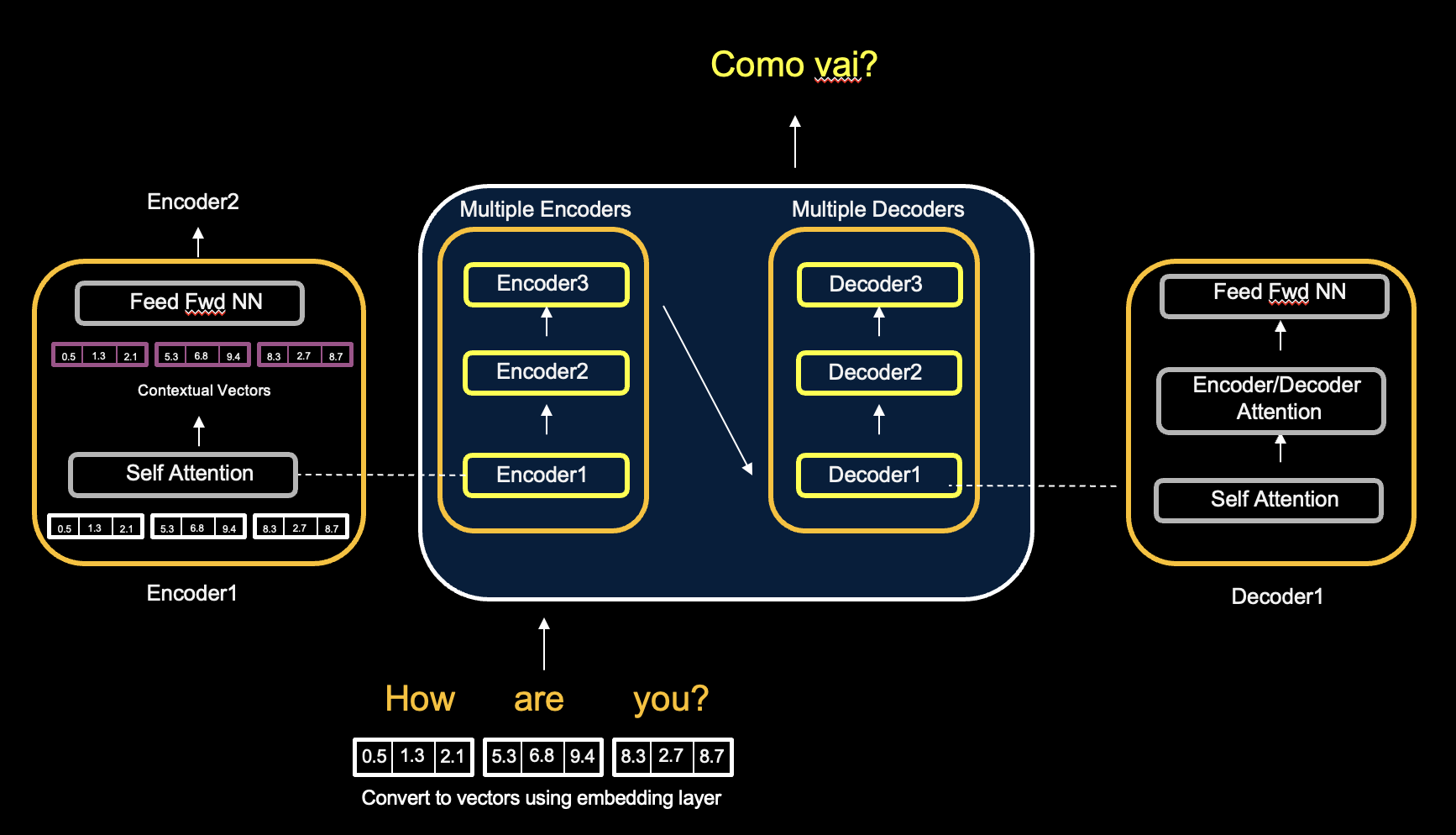
Transformer Architecture — Multiple Encoder & Decoder Layers
05
Self Attention
Queries, Keys & Values
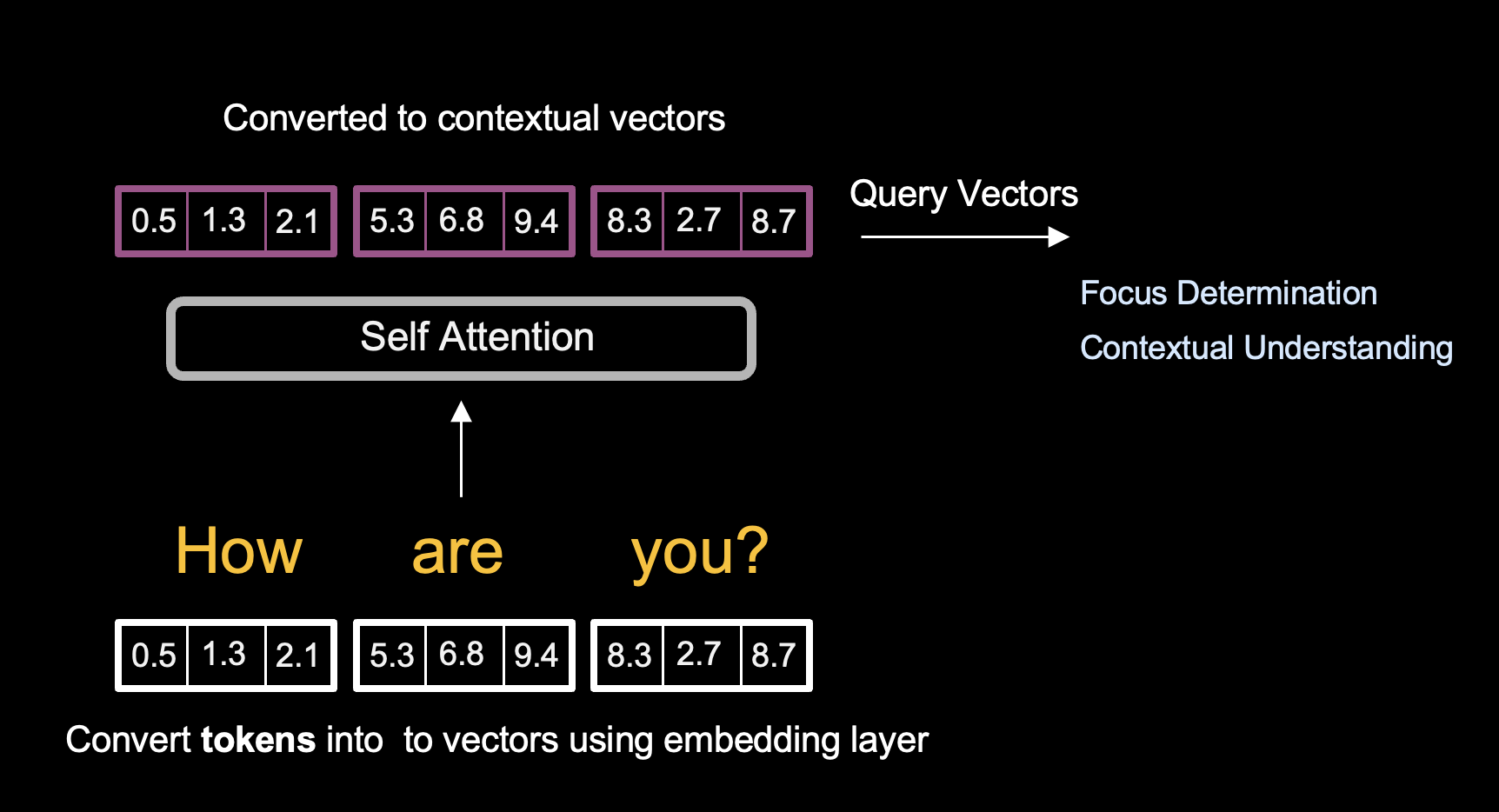
Query, Key & Value Vectors — Self Attention Computation
You may be wondering how Self Attention knows which word has a dependency in order to do contextual vector embedding. First, let's discuss tokens. A vector is a numerical representation of a token. When referencing input vectors, we're referring to tokens converted into numbers.
Within our input vectors, there are three important inputs models compute for contextual embedding: queries, keys, and value vectors.
Query Vector
Represents the token to calculate attention. Determines the importance of other tokens in the context of the current token. Uses Focus Determination and Contextual Understanding to decide which parts of the sequence to attend to.
Key Vector
Represents all tokens in the sequence and is compared to query vectors to calculate an attention score for accuracy. This is one reason multiple encoders and decoders are used in the transformer architecture.
Value Vector
Holds the information aggregated to form the output of the attention mechanism. Contains data using weights the model uses to compute an attention score. The weighted values are passed to the neural network to preserve and aggregate relevant context from the entire sequence.
Focus Determination helps the model decide which parts of the sequence to focus on for each specific token by calculating the soft attention (dot-product) between a query vector and all key vectors. Contextual Understanding captures relationships between the current token and the rest of the sequence to identify dependencies and context.
06
Overview
Full Architecture
That covers the core concepts of how transformers work. There is a lot more detail that goes into the overall architecture, but below is a complete diagram of the transformer architecture for further reference and reading.
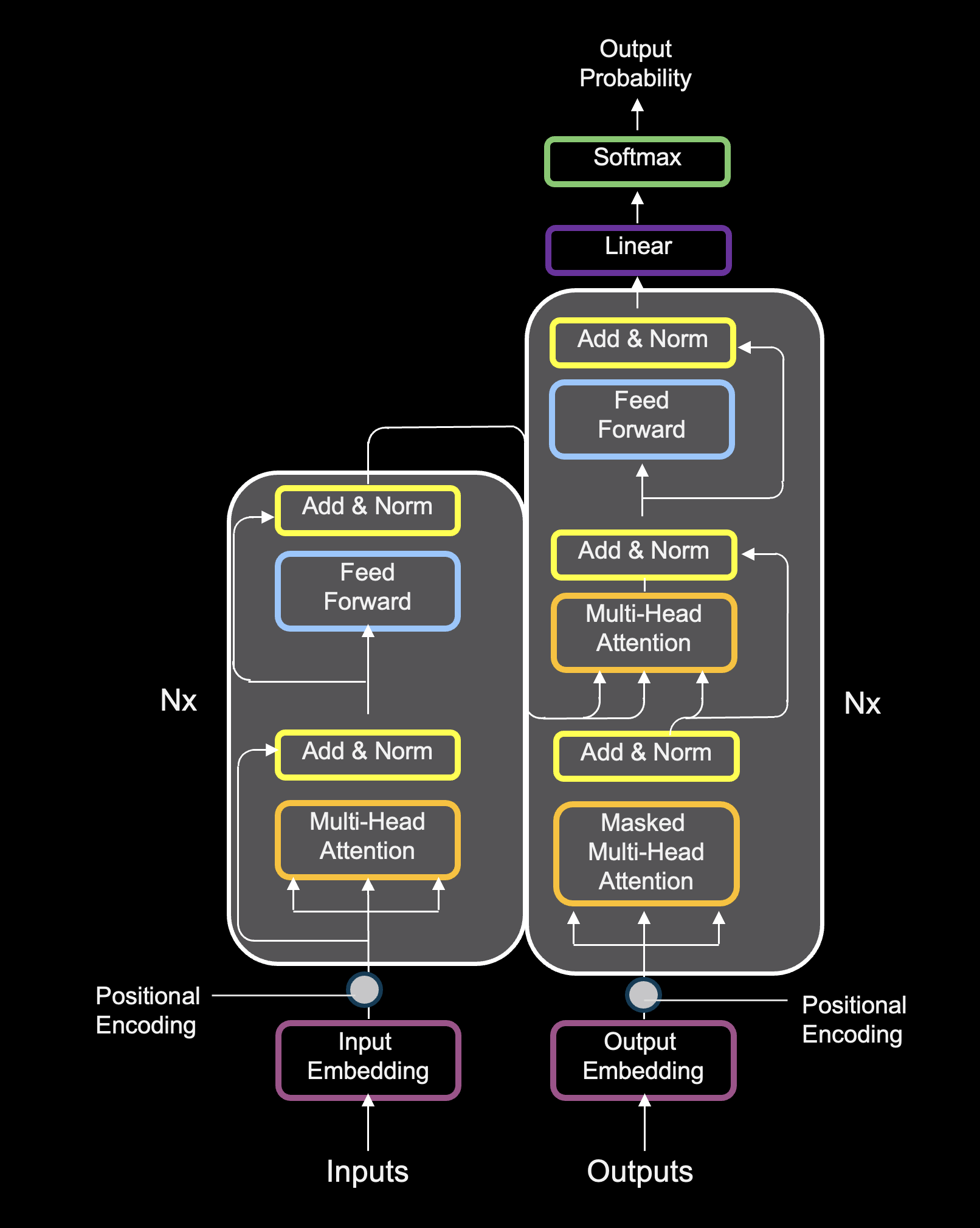
Complete Transformer Architecture — Full Reference Diagram